Probability Distributions and the Central Limit Theorem#
Mickey Atwal, Cold Spring Harbor Laboratory
Here we will visualize, in Python, a few important distributions that commonly appear in science and statistics. A more exhaustive list of statistical distributions can be found in the stats module of SciPy.
At the end of this IPython Notebook we will demonstrate what is arguably the most famous and profound theorem in statistics: the Central Limit Theorem.
from __future__ import division
import scipy.stats as stats
%pylab inline
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
Discrete Distributions#
\(\mathbf{BINOMIAL}\):The probability of observing \(n\) successes, each with a probability \(p\), out of \(N\) attempts. $\( P(n;N,p)=\displaystyle \left( \frac{N!}{n!(N-n)!} \right) p^n (1-p)^{N-n} \)$
mean=\(Np\), variance=\(Np(1-p)\)
Example: what is the probability of getting 2 heads out of 6 flips of a fair coin?
N=6
p=0.5
n=arange(0,20)
y=stats.binom.pmf(n,N,p)
plt.plot(n,y,'o-')
plt.title('Binomial: N=%i , p=%.2f' % (N,p),fontsize=15)
plt.xlabel('n',fontsize=15)
plt.ylabel('Probability of n',fontsize=15)
plt.show()
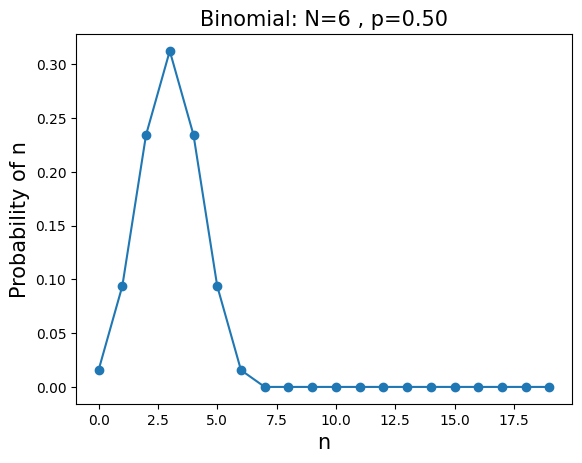
\(\mathbf{POISSON}\): The probability of observing \(n\) low-probability successes when the average number of successes is \(\mu\) $\( P(n;\mu)=\frac{\mu^n e^{-\mu}}{n!} \)$
mean=\(\mu\), variance=\(\mu\)
Example: what is probability of observing 60 new mutations in the genome of a child given that the average number of new mutations is 50?
u=3
n=arange(0,15)
y=stats.poisson.pmf(n,u)
plt.plot(n,y,'o-')
plt.title('Poisson: $\mu$ =%i' % u,fontsize=15)
plt.xlabel('n',fontsize=15)
plt.ylabel('Probability of n',fontsize=15)
plt.show()
Continuous Distributions#
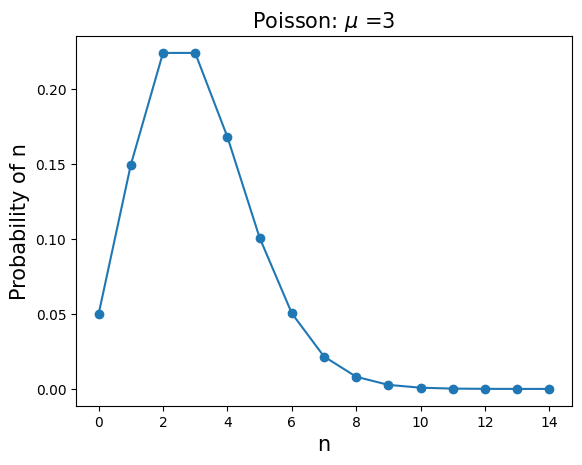
\(\mathbf{GAUSSIAN (NORMAL)}\): \(P(x;\mu,\sigma)=\displaystyle \frac{1}{\sqrt{2 \pi \sigma^2}} \exp{\displaystyle \left( -\frac{(x-\mu)^2}{2 \sigma^2} \right) }, \hspace{1in} x \in [-\infty;\infty]\)
mean=\(\mu\), variance=\(\sigma^2\)
This distribution appears as the large N limit of the binomial distribution and the Central Limit Theorem.
u=5 # mean
s=1 # standard deviation
x=arange(0,15,0.1)
y=(1/(np.sqrt(2*np.pi*s*s)))*exp(-(((x-u)**2)/(2*s*s)))
plt.plot(x,y,'-')
plt.title('Gaussian: $\mu$=%.1f, $\sigma$=%.1f' % (u,s),fontsize=15)
plt.xlabel('x',fontsize=15)
plt.ylabel('Probability density',fontsize=15)
plt.show()
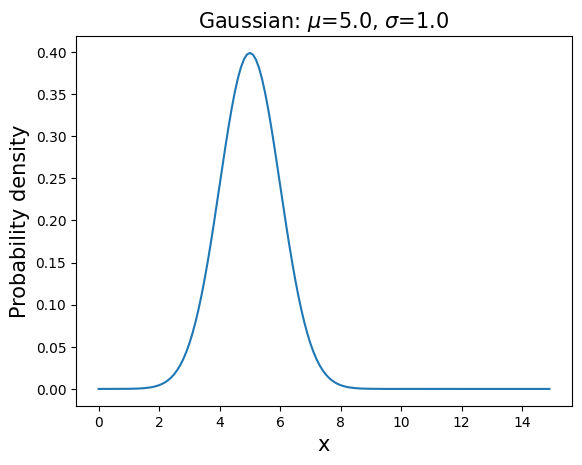
\(\mathbf{EXPONENTIAL}\): \(P(x;k)=k e^{-kx}, \hspace{1in} x \in [0,\infty], \hspace{0.1in} k>0\)
mean=\(1/k\), variance=\(1/k^2\)
This distribution describes the time intervals in a homogeneous Poisson process.
k=0.4
x=arange(0,15,0.1)
y=k*exp(-k*x)
plt.plot(x,y,'-')
plt.title('Exponential: $k$ =%.2f' % k,fontsize=15)
plt.xlabel('x',fontsize=15)
plt.ylabel('Probability density',fontsize=15)
plt.show()
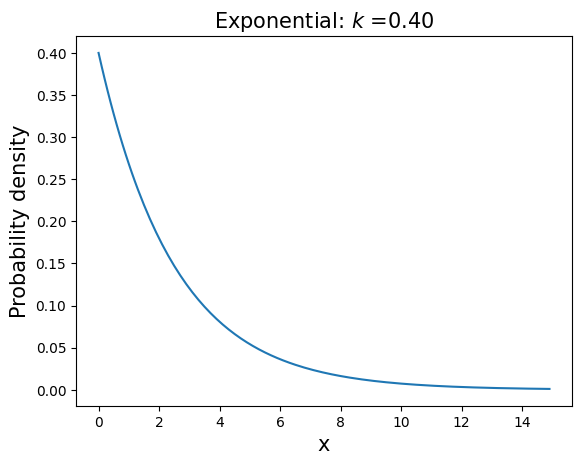
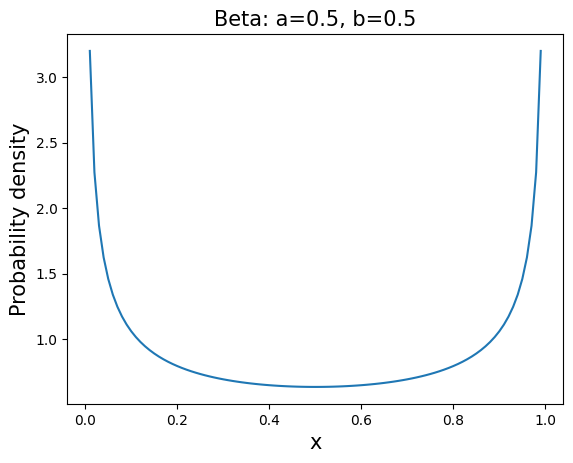
\(\mathbf{BETA}\): \(P(x;\alpha,\beta)=\displaystyle \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1}\), \(\hspace{1in} x \in [0;1], \hspace{0.1in} \alpha>0, \hspace{0.1in}\beta>0\)
mean=\(\displaystyle \frac{\alpha}{\alpha+\beta}\), variance=\(\displaystyle \frac{\alpha \beta}{(\alpha + \beta)^2(\alpha + \beta +1)}\)
This distribution appears often in population genetics and Bayesian inference.
a=0.5
b=0.5
x=arange(0.01,1,0.01)
y=stats.beta.pdf(x,a,b)
plt.plot(x,y,'-')
plt.title('Beta: a=%.1f, b=%.1f' % (a,b) , fontsize=15)
plt.xlabel('x',fontsize=15)
plt.ylabel('Probability density',fontsize=15)
plt.show()
Central Limit Theorem#
Take the mean of \(n\) random samples from ANY arbitrary distribution with a well defined standard deviation \(\sigma\) and mean \(\mu\). As \(n\) gets bigger the distribution of the sample mean will always converge to a Gaussian (normal) distribution with mean \(\mu\) and standard deviation \(\sigma/\sqrt{n}\).
Colloquially speaking, the theorem states that the average (or sum) of a set of random measurements will tend to a bell-shaped curve no matter the shape of the original meaurement distribution. This explains the ubiquity of the Gaussian distribution in science and statistics. We can demonstrate the Central Limit Thereom in Python by sampling from three different distributions: flat, exponential, and beta.
from functools import partial # provides capability to define function with partial arguments
N=10000 # number of times n samples are taken. Try varying this number.
nobb=101 # number of bin boundaries on plots
n=np.array([1,2,3,5,10,100]) # number of samples to average over
exp_mean=3 # mean of exponential distribution
a,b=0.7,0.5 # parameters of beta distribution
dist=[partial(np.random.random),partial(np.random.exponential,exp_mean),partial(np.random.beta,a,b)]
title_names=["Flat", "Exponential (mean=%.1f)" % exp_mean, "Beta (a=%.1f, b=%.1f)" % (a,b)]
drange=np.array([[0,1],[0,10],[0,1]]) # ranges of distributions
means=np.array([0.5,exp_mean,a/(a+b)]) # means of distributions
var=np.array([1/12,exp_mean**2,a*b/((a+b+1)*(a+b)**2)]) # variances of distributions
binrange=np.array([np.linspace(p,q,nobb) for p,q in drange])
ln,ld=len(n),len(dist)
plt.figure(figsize=((ld*4)+1,(ln*2)+1))
for i in range(ln): # loop over number of n samples to average over
for j in range(ld): # loop over the different distributions
plt.subplot(ln,ld,i*ld+1+j)
plt.hist(np.mean(dist[j]((N,n[i])),1),binrange[j],density=True)
plt.xlim(drange[j])
if j==0:
plt.ylabel('n=%i' % n[i],fontsize=15)
if i==0:
plt.title(title_names[j], fontsize=15)
else:
clt=(1/(np.sqrt(2*np.pi*var[j]/n[i])))*exp(-(((binrange[j]-means[j])**2)*n[i]/(2*var[j])))
plt.plot(binrange[j],clt,'r',linewidth=2)
plt.show()
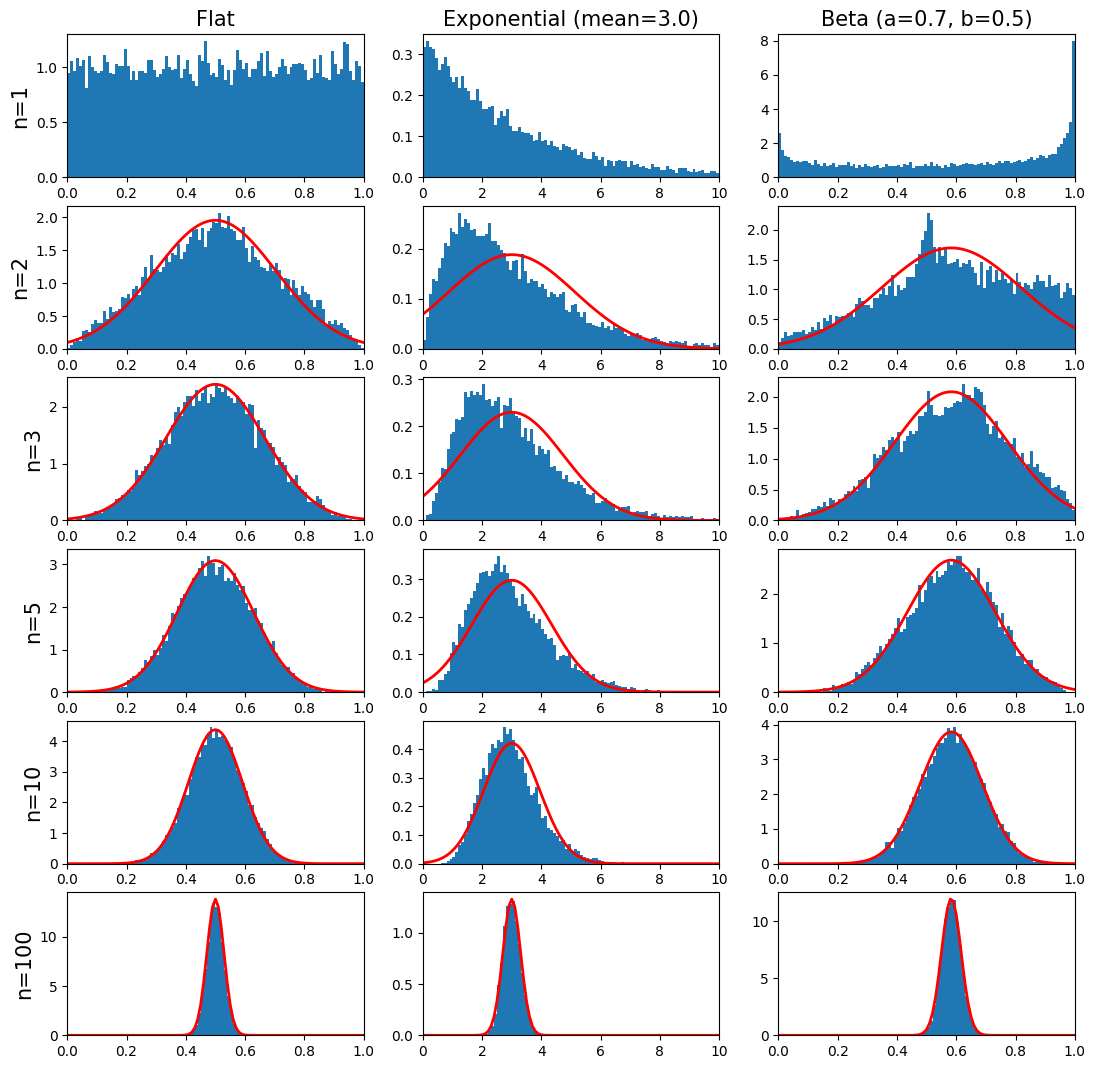
In the graphs above the red curve is the predicted Gaussian distribution from the Central Limit Thereom. Notice that the rate of convergence of the sample mean to the Gaussian depends on the original parent distribution. Also,
the mean of the Gaussian distribution is the same as the original parent distribution,
the width of the Gaussian distribution scales as \(1/\sqrt{n}\).